Die Suchmaschine unterscheidet zwischen einem Setup- und einem Run-Modus. Im Setup-Modus wird der Index aufgebaut; Abfragen sind nicht möglich. Im Run-Modus sind alle internen Datenstrukturen read-only, d.h. Aktualisierungen des Index sind z.B. in diesem Modus nicht möglich. Der Übergang vom Setup- in den Run-Modus geschieht durch Dumpen des Index: Nach Parsen und Indexieren aller Dokumente wird der Index komprimiert und in eine Datei geschrieben. Anschließend wird diese Datei von einer zweiten Instanz der Suchmaschine eingelesen, der Index wird im Speicher aufgebaut und der Run-Modus aktiviert.
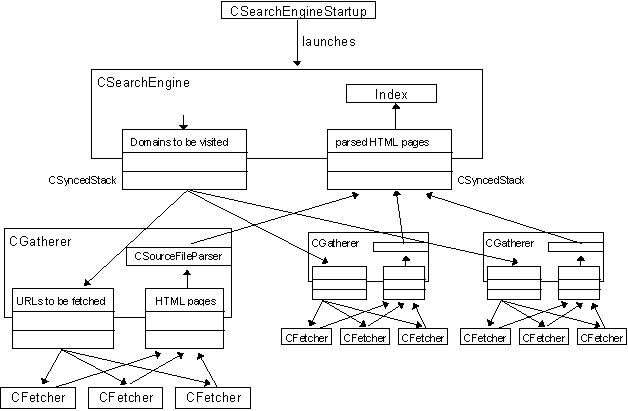
Zentrale Komponente der Suchmaschine ist eine Instanz der Klasse CSearchEngine. Die drei wichtigsten Methoden dieser Klasse sind go() zum Aufbau bzw. Einlesen des Index, optimize() zum Komrimieren und Dumpen des Index und handleRequest() zur Abarbeitung einer Suchanfrage.
Das Einlesen der zu indexierenden Seiten geschieht über Instanzen der Klassen CGatherer und CFetcher. Gatherer behandeln dabei immer eine komplette Domain, während Fetcher für das Einlesen einzelner Seiten zuständig sind. Sowohl Gatherer als auch Fetcher sind als Threads implementiert, um die Zeit des Netzwerkzugriffs möglichst effektiv für andere Aufgaben (Parsen, Indexieren) nutzen zu können.
Die Kommunikation zwischen der Suchmaschine und den Gatherern geschieht über eine Stack. Auf diesen legt die Suchmaschine bei Aufruf der Methode go() die URLs der Indexseiten aller einzulesenenden Internet-Domains. Die einzelnen Gatherer nehmen jeweils eine Domain nach der anderen vom Stack und arbeiten sie ab. Nach Abbarbeitung aller Domains terminieren die Gatherer-Threads.
Jeder Gatherer verwaltet eine Reihe von CFetcher-Objekten. CFetcher sind für das Einlesen und Parsen einer einzelnen URL zuständig. Die Kommunikation zwischen Gatherer und Fetchern geschieht ebenfalls über Stacks: Der gatherer legt alle inzulesenden URLs auf einem Stack ab. Die Fetcher nehmen immer eine URL vom Stack, lesen und parsen das zugehärige Dokument und legen anschließend das geparste Dokument auf einen zweiten Stack. Dieser Vorgang wiederholt sich, bis keine URL mehr auf dem Stack liegt. Die geparseten Dokumente werden vom Gatherer vom zweiten Stack genommen und über einen weiteren Stack dem Indexierer zugänglich gemacht. Zusätzlich legt der Gatherer alle im Dokument referenzierten URLs der gleichen Domain auf den für die Fetcher zugänglichen Stack.
Die Struktur des endbenutzerseitigen Teils von Infubot kann grob anhand des folgenden Schemas beschrieben werden (Dies ist die Implementierung mit servlet):
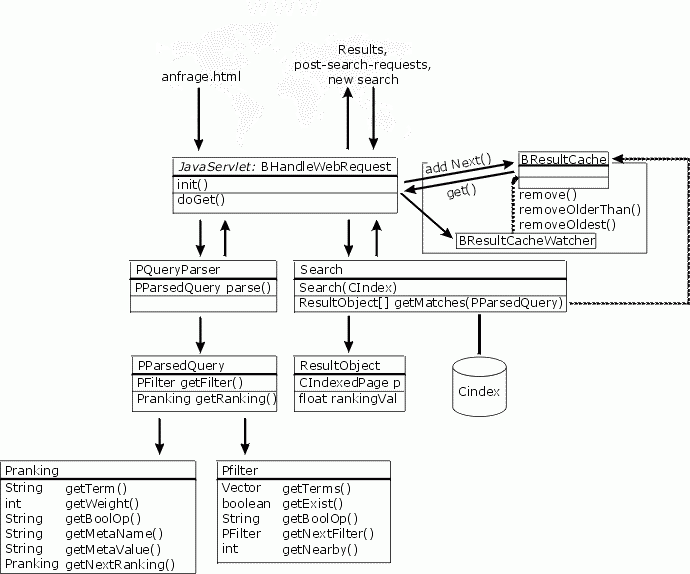
Das Servlet, das mit dem Nutzer kommuniziert, ist in der Klasse BHandleWebRequest implementiert. Beim Start des Servlets wird die für diese Instanz des Servlets vorgesehene Indexdatei in den Hauptspeicher eingelesen. Infubot wartet jetzt auf Nutzeranfragen.
Aus einem Formular, das als dezidierte HTML-Datei vorliegt, wird die Anfrage gestartet. Das Servlet ruft nun den Anfrageparser auf, der die Anfragesprache interpretiert und das Stemming der Suchworte durchführt. Dies führt zu einem Objekt vom Typ PParsedQuery, welches an die Methode getMatches der Klasse Search übergeben wird.
Der Rückgabetyp von getMatches ist ResultObject[]. Dieses Objekt wird von der Hilfsklasse Bhtml (nicht im Bild) als HTML-Dokument mit Möglichkeit zum Browsen durch den Ergebnisraum aufbereitet und an den Nutzer zurückgeschickt.
Beim Initialisieren des Servlets wird auch ein statisches Objekt vom Typ BResultCache, sowie ein Thread BResultCacheWatcher gestartet. Der Resultcache speichert solche Suchanfragen zwischen, deren Ausgabe nicht vollends auf die erste Ergebnisseite paßte. Auf diese Weise muß für Post-search-requests keine erneute Suche gestartet werden, vielmehr wird nur das ResultObject-Array aus dem Zwischenspeicher gelesen. Der Cacheschlüssel für die einzelnen Arrays, sowie der Offset wird in der URL kodiert.
Aufgabe von BResultCacheWatcher ist es nun, in definierten Intervallen (alle s Sekunden) die größe des Caches zu überprüfen. Dabei löscht der Thread alle Elemente aus dem Cache, die älter sind als m Minuten. Erreicht der Cache dennoch eine kritische Größe von n Objekten, werden die ältesten Objekte gelöscht, bis der Cache wieder die gewünschte Maximalkapazität unterschreitet. s, m und n sind vom Infubot-Administrator konfigurierbar.