Author: Simon Berg
Since Infubot is seperated into the part that will build the index and the one serving the clients,
this part describes the architecture of the servlet-part of Infubot.
It will explain how a user-request to the search-engine is handled and how other components are called by the
main servlet.
It will also explain the functionality of the HTML enduser-interface.
At the moment, the classfile of the servlet is named BHandleWebRequest.class. This one is invoked by the underlying
servlet-engine and will process http-requests of method-type GET. See website of W3C
for further details on http-protocol.
The servlet will load the searchable indexfile into RAM of the server. It then processes requests passed to it by a
HTML-form (anfrage.html in original distribution). Here are the keys that the servlet will expect:
The following two keys are optional and only used by servlet-generated links, so do not edit:
When a request is passed to the servlet, it will make some binary decisions shown below:
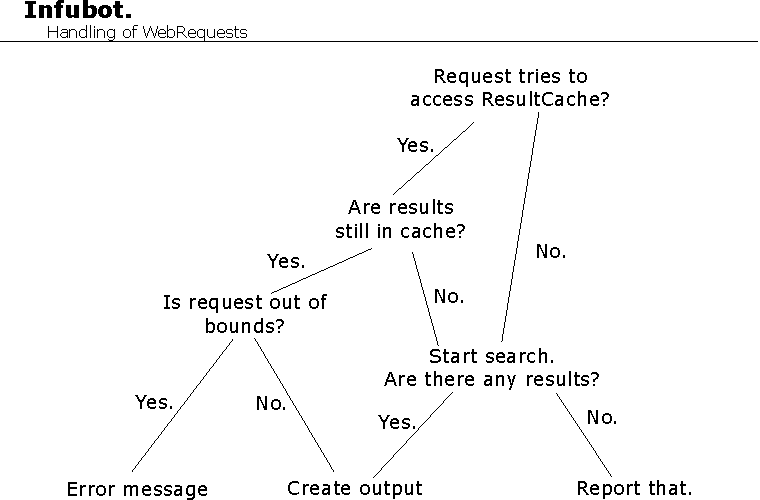
As you can see, search is performed only if a previous search was not stored in cache. Requests will be stored
if the output did not fit on one page. The number of elements to be presented on one page is adjustable using
a .properties-file. For valid values of this file, see README and javadoc.
When search has to be started, the servlet creates a PParsedQuery-object using PQueryParser. The former
is passed to the search-method. The returned ResultObejct[] is converted to HTML by Bhtml.displayResults()
and sent to the user. displayResults() will also add links for the next/previous result-page.
When the servlet is initialized, it runs a thread BResultCacheWatcher that will watch the cache not to grow to much.
The configuration of startup-parameters for this one is also done in the .properties-file.
The cleanup of cache could have been done at the end of every request. But since this feature was designed to reduce overhead on
heavy loads and to increase performance, this way didn't seem apropriate.
Every Request is encasulated in an obejct that is called BWebRequest. Every information needed for handling a distinct
request, is stored here in a simple way. And - it's rather OOP :).
Since there were no explicit specifications for this part of the implementation, the design of the servlet is kind of homemade.
In the programmer's opinion it fits the requirements quite good. The servlet allows user-configuration before startup and is some
kind of adaptive for different environments. One big improvement - configuration at runtime - should be made in the future.
The servletrunner servlet-engine by Sun doesn't initialize the servlet at it's startup. This is why loading of indexfile
is done when the first request arrives. This first user will have to wait until index was loaded, so a thread informs the user through
the web-interface, that loading will take some time.
Servlet-engines other than servletrunner are able to run the init()-method of the servlet when the servlet-engine itself comes
up.
So, loading of index should be able to be switched from doGet() to init() in a future/production-release.
There are two sides of the GUI: the HTML-form to submit a query and presentation of results.
Let's see what we're talking about.
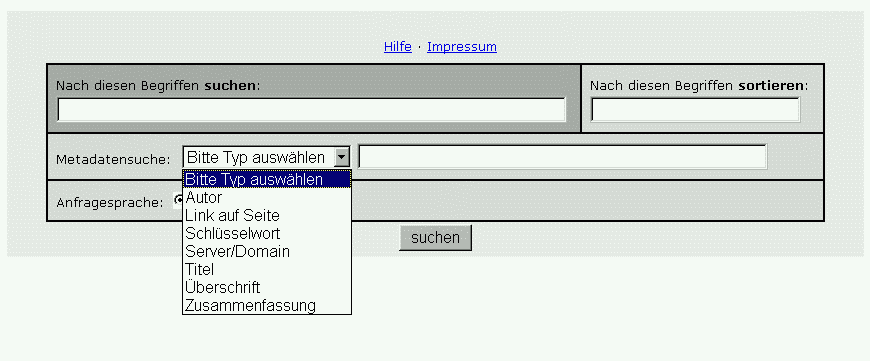
Currently this is only available in German.
The input-field in darker grey is the simple part of the query. Just type in a few words and see what will happen.
The fields in lighter gray are optional. This is for advanced seach. A distinction between simple and advanced search
using two different forms didn't seem as attractive as this one. The user recognizes the possibility for a simple search
and will not have to click into another form for advanced search. In this approach, advanced search is not a hidden feature.
However, it is at your fingertips all the time and the user is invited to play with the supplementary features.
Every query is recoverable using the 'back'-button of the browser. Further on, it is easily to store even more complex searches
using the bookmarking-feature of common browsers. That's why requests are actually sent to the search engine using HTTP-GET.
POST won't allow this useful feature.
The two links on top of the form are currently NYI, but weren't even specified. Their functionallity should really be added
in the future or by people administering an installation of Infubot.

Each result is presented in a seperate table. At the top of every page one can see the filter-expression that was searched for, how
many results have been found and which part of the result-space is displayed on the current page.
At the bottom you can see optional links (it's only one in the example) for navigating back or forward in the result-space.
The result-table itself has got up to three different rows:
The implementation of this part is really straightforward, it matches the specs despite support for relevance-feedback which is currently not supported by the seach-engine.
Simon Berg, last modofied Feb-22-1999