Der Index ist die zentrale Datenstruktur der Suchmaschine. Seine Hauptaufgabe besteht darin, Verweise von Worten auf Dokumente (und umgekehrt) zu verwalten.
Der Aufbau des Index aus den im Web gefundenen Dokumenten besteht aus zwei Schritten:
Der temporäre Index eignet sich gut zum Anfügen von Worten und Dokumenten, ist jedoch sehr langsam. Aus diesem Grunde wird er nach Einlesen aller zu indexierenden Dokumente optimiert. Der optimierte Index ist read-only und schnell.
Im folgenden wird der Aufbau des optimierten Index beschrieben.
Der Index wird aus CPage-Objekten erstellt. Jedes dieser Objekte enthält eine Liste aller in dem Dokument vorkommenden Wortstämme, wobei Stop-Worte bereits entfernt wurden. Zu jedem Wort ist seine Position innerhalb des Dokuments vermerkt.
Der Index besteht aus drei Komponenten:
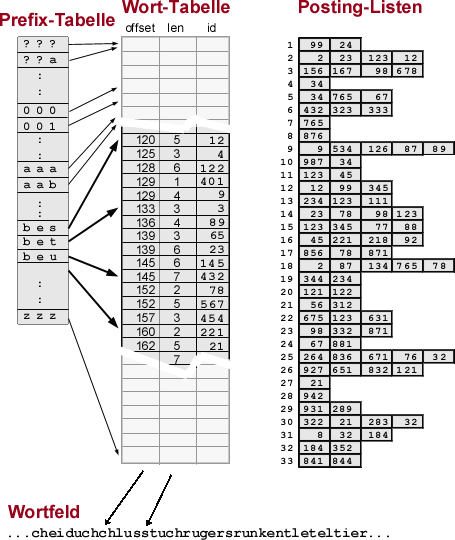
Die Wortliste beinhaltet im Wesentlichen Abbildungen von Zeichenketten (Wortstämmen) auf Wort-IDs. Bei einer Suchanfrage kann so zu jedem indexierten Wort eine eindeutige ID ermittelt werden. Diese ID fungiert als Index in die Postinglisten, in denen für jeden Wortstamm eine Liste aller damit verknüpften Dokumente samt Ranking-Informationen verwaltet wird. Innerhalb der Postinglisten liegen Dokumente als numerische IDs vor. Diese IDs dienen als Index in die Dokument-Liste, wo sie auf das zugehörige CIndexedPage-Objekt verweisen.
Interessant sind vor allem die Posting-Listen und vor allem die Wort-Liste, da deren Implementierung teilweise sehr stark von den bei den letzten Treffen festgelegten Strukturen abweicht. Die Dokument-Liste ist unverändert geblieben, so daß sie hier nicht näher behandelt wird.
Die folgende Abbildung zeigt den prinzipiellen Aufbau des Index:
Die Postinglisten der einzelnen Wortstämme werden als zweidimensionales Array verwaltet. Als Index der ersten Dimension fungiert die ID des Wortstammes. Die zweite Dimension besteht aus einer als Array implementierten Liste von Posting-Einträgen. Jeder Posting-Eintrag repräsentiert ein mit diesem Wort verknüpftes Dokument und hat folgendes Format:
|
Bit 0-22 |
ID eines verknüpften Dokuments |
|
Bit 23 |
unbenutzt |
|
Bit 24 |
Kommt das Wort in diesem Dokument im Titel vor? |
|
Bit 25 |
Kommt das Wort in diesem Dokument in einer Überschrift vor? |
|
Bit 26 |
Ist das Wort in diesem Dokument markiert? |
|
Bit 27-31 |
Ranking |
Auf die einzelnen Felder eines Posting-Eintrags kann über Methoden der Klasse CMask zugegriffen werden.
In der aktuellen Implementierung werden die Postinglisten - entgegen der ursprünglichen Planung - nicht komprimiert. Hier müßte getestet werden, ob eine Komprimierung Sinn macht. Dafür spricht, daß die Postinglisten (neben den DocReps) den bei weitem meisten Speicher benötigen. Dagegen spricht, daß durch die Kodierung als Bitmasken die vorkommenden Werte relativ gleichverteilt sind, was eine Komprimierung erschwert.
Die Wortliste ist der komplexeste Teil des Index, da hier Größe und Geschwindigkeit eine sehr große Rolle spielen. Die Wortliste besteht im wesentlichen aus Abbildungen von Wortstämmen auf Wort-IDs, die zum Zugriff auf die Postinglisten benötigt werden. Darüber hinaus sind die verwalteten Wortstämme alphabetisch sortiert, um auch Abfragen mit Wildcards zu ermöglichen.
Zentraler Teil der Wortliste ist die als Array implementierte Wort-Tabelle. Für jeden indexierten Wortstamm existiert ein 8 Byte langer Eintrag in dieser Tabelle. Die Einträge in der Worttabelle sind in aufsteigender alphabetischer Reihenfolge der zugehörigen Wortstämme sortiert. Jeder Eintrag dieser Tabelle hat folgendes Aussehen:
|
Bit 0-23 |
Wort-ID (Bit 23 ist immer 0!) |
|
Bit 24-31 |
#verknüpfter Dokumente (Wurzel) |
|
Bit 32-39 |
Länge des Wortstamms |
|
Bit 40-63 |
Offset im Wortfeld |
Die Bits 32-63 werden nur für interne Zwecke verwendet, während die Bits 0-31 den sog. Wort-Link bilden, der von einigen Methoden des Index als Wort-ID zurückgeliefert wird.
Die Wortstämme selber werden in einer einzigen langen Zeichenkette - dem Wortfeld - verwaltet. Die in der Worttabelle enthaltenen Offsets sind somit keine Pointer auf Zeichenketten, sondern Indizes in diese Zeichenkette. Die folgende Abbildung verdeutlicht die zugrundeliegende Idee:
Offset 1, Länge 4: "bach" Offset 5, Länge 7: "buecher" Offset 5, Länge 9: "buecherei" Offset 14: Länge 6: "bruder" |
Der Wort-Tabelle vorgeschaltet ist eine Prefix-Tabelle. Die Präfix-Tabelle enthält für jeden 3-buchstabigen Präfix den Index in die Wort-Tabelle, an dem sich der erste mit diesem Präfix beginnende Wortstamm befindet. Die Präfix-Tabelle ist als Array von Integers implementiert und belegt unabhängig von der Größe der Worttabelle ca. 128 KB Speicher. Da jeder Zugriff auf die Wort-Tabelle über die Präfix-Tabelle geschieht, müssen die ersten drei Buchstaben eines Wortstammes nicht im Wortfeld abgelegt werden (Ihre Übereinstimmung ist ja schon über die Präfix-Tabelle überprüft) . Bei einem aus 1.000.000 Worten bestehenden Index bedeutet dies z.B. eine Speicherersparnis von 3 MB. Zusätzlich beschleunigt die Präfix-Tabelle die Suche nach Wortstämmen, da sie relativ enge Grenzen für die Binärsuche vorgibt.
Die hier beschriebenen Optimierungen verringern die Größe der Wortliste um ca. 40% gegenüber dem ursprünglichen Design. Bei einer durchschnittlichen Wortlänge von 9,4 Buchstaben werden pro Wort nur ca. 12 Byte in der Wortliste benötigt; beim alten Design wären es (je nach Java-Implementierung) mindestens 20.
Um Aktualisierungen des (nicht-optimierten) Index vornehmen zu können müssen folgende Änderungen im Source-Code vorgenommen werden: