Page ThesisAPIBrowsingArchitecture
Auf dieser Seite bündele ich Ideen, Erkenntnisse, Beschlüsse und Dokumente zur Architektur des Systems.
Ideen
((content))
Erkenntnisse
Methode zur Speicherung von relevanten Werten
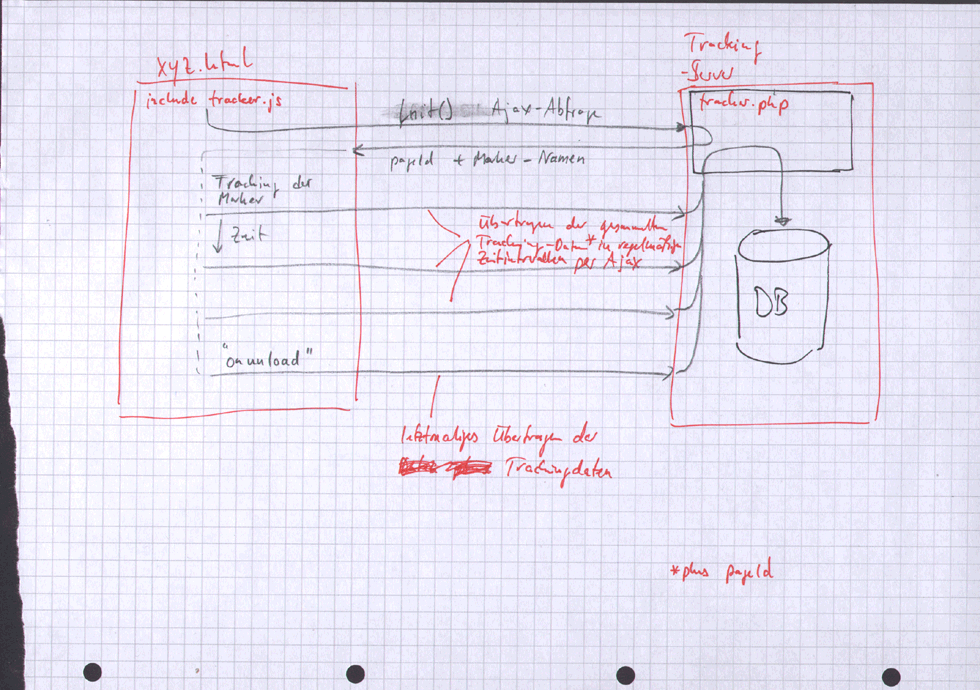
Zunächst war mein Plan, das Scrolling der Webseiten mittels des onscroll-Events zu tracken, also immer nur dann, wenn sich auch tatsächlich etwas ändert. Das scheitert jedoch daran, dass Firefox den onscroll-Event nicht auslöst, wenn mittels des Maus-Scrollrades gescrollt wird. Ausserdem muss auch getrackt werden, ob die Fenstergrösse verändert wird (da das Einfluß auf den Fluss des Gesamtdokumentes und somit auf die Position der Marker hat). Ich habe mich deswegen dazu entschlossen, sekündlich zu tracken, was das Datenaufkommen erhöht, mir aber viel Kopfzerbrechen bezüglich Browserinkompatibilitäten erspart. Ich verlagere die Reduktion der Datensätze auf wirklich relevante Teile somit auf den Server. Dieser muss aufeinanderfolgende gleiche Datensätze möglichst sinnvoll und kompakt zusammenfassen, zum Beispiel wenn der Nutzer eine Webseit für einen längeren Zeitraum ohne Aktivität geöffnet lässt und die Tracking-Daten sich nur zeitlich gesehen unterscheiden.Ansteuern von MarkedObjects
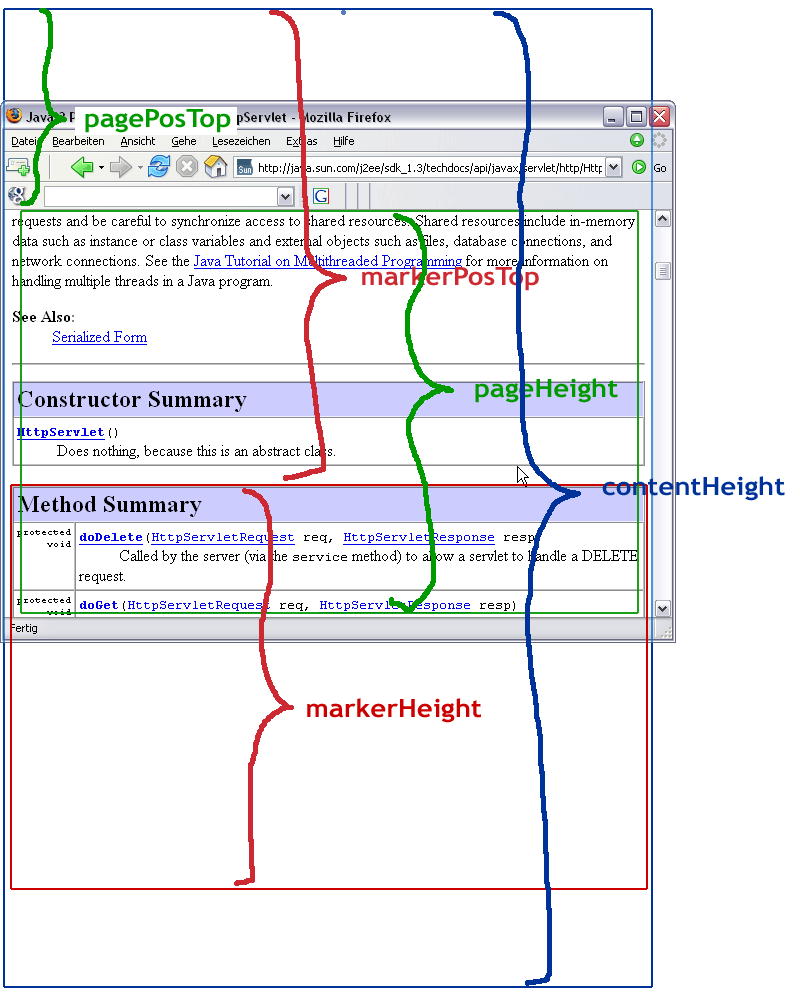
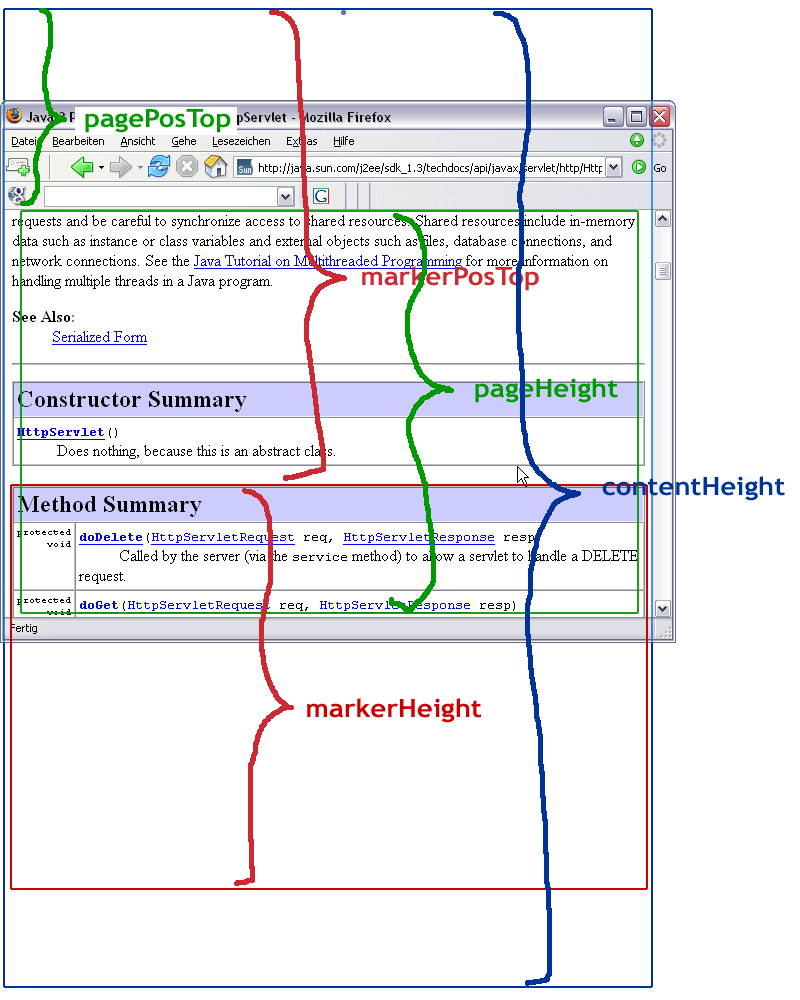
Um die Position von Objekten im Seitenfluss zu tracken, müssen zunächst Referenzen auf diese Objekte gefunden werden. Zwei Varianten müssen dabei unterschieden werden:- Webseiten, in deren Quelltext man eingreifen kann/möchte und Marker manuell einfügt. Beispielsweise durch Setzen des name-Attributes für Block- und Inline-Elementen (<div name="abschnitt2">Ist dieser Text hier gut sichtbar?</div>).
- Webseiten, deren Quelltext bereits eine wiederkehrende, hinreichende Menge von Mustern enthält, die man als zur Identifikation der zu trackenden Objekte nutzen kann (API-Doc: <A NAME="method_summary"><!-- -→</A>).
Das automatische Durchsuchen des Quelltextes nach Markierungen, z.B. durch parsen von body.innerHtml, ist sicherlich (zu) Ressourcenhungrig. Ich halte es deshalb für die einzig praktikable Lösung, wenn man mit der Webseite auch gleich die Liste aller _name_-Attribute der zu trackenden Objekte übergibt, die dann über getElementsByName, gezielt ausgelesen/angesprochen werden können.
Beschlüsse
((content))
Dokumente
((content))
Comments
- Wie funktioniert die Datensammlung und der Übertrag zum Server?:
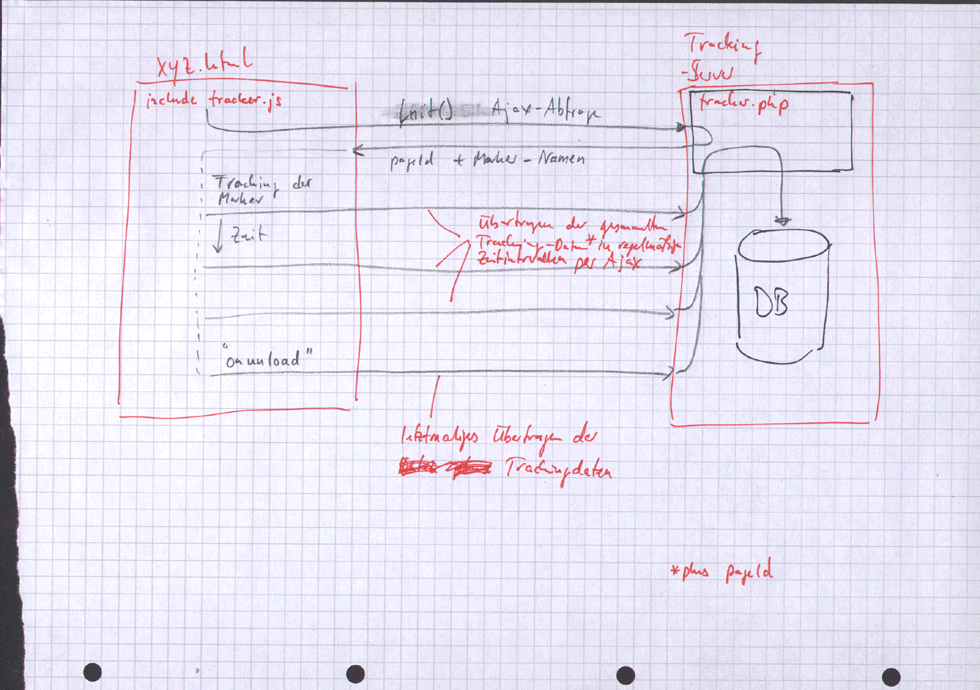
- Welche Daten sind überhaupt relevant und sollten getrackt werden?:
{kind=link}
{kind=link}