Zwei Hauptprobleme der Erkennung isolierter Wörter sind die Endpunkt-Erkennung und Verzerrung des zeitlichen Ablaufs. Das Problem der zeitlichen Koordinierung kann durch die dynamische Programmierung gelöst werden, mittels derer die beste Zuordnung der Zeitachsen eines unbekannten Wortes auf jedes Vergleichsmuster bestimmt werden kann.
Das Prinzip. Ein Wort kann unterschiedlich schnell gesprochen
werden. Daher stimmt die zeitliche Länge des zu erkennenden Wortes
normalerweise nicht mit derjenigen des gespeicherten Musters überein.
Dies würde bei vielen Methoden des Mustervergleichs dazu führen,
daß die Ähnlichkeit als gering bewertet wird. Daher ist eine
Zeitnormierung
erforderlich, bei der die Wörter zeitlich gedehnt oder gestaucht werden.
Dies darf jedoch nicht einfach proportional erfolgen, da die zeitliche
Variation nicht alle Wortteile gleichermaßen betrifft (z. B. bleiben
,,t`` und ,,b`` fast unverändert, während die zeitliche Länge
von ,,a`` und ,,s`` sehr unterschiedlich sein kann). Ein Normierungsverfahren,
das diese Tatsache berücksichtigt, ist die Dynamische Programmierung
bzw. das Dynamic Time Warping.
Abb.2: Nichtlineare zeitliche Verzerrung zwischen Realisierungen zweier Wörter
Das Problem ist in der Abbildung verdeutlicht. Die waagerecht bzw. senkrecht
aufgetragenen (eindimensionalen) Merkmalsfolgen entsprechen zwei Realisierungen
desselben Wortes. Die unterschiedliche zeitliche und artikulationsgeometrische
Strukturierung der beiden Wortproduktionen schlägt sich in der relativen
Verzerrung ihrer Zeitskalen nieder. Eine mutmaßliche Zuordnung zwischen Zeitpunkten korrespondierender
Artikulationsgesten ist als Pfad im Produktgitter der Skalen markiert.
Eine mutmaßliche Zuordnung zwischen Zeitpunkten korrespondierender
Artikulationsgesten ist als Pfad im Produktgitter der Skalen markiert.
Ist ein Wortschatz ![]() vom Umfang L sowie ein kurzzeitanalysierte Einwortäußerung in
Gestalt der Merkmalvektorfolge
vom Umfang L sowie ein kurzzeitanalysierte Einwortäußerung in
Gestalt der Merkmalvektorfolge ![]() gegeben, so besteht die
Einzelworterkennungsaufgabe darin, die Identität
des mutmaßlich gesprochenen Wortes zu ermitteln. Dabei stehen nur
Elemente des Erkennungswortschatzes W zur Debatte. Das Ziel der
Auslegung eines Worterkenners ist die Minimierung der
Wortfehlerrate,
also der zu erwartenden Häufigkeit falscher Wortentscheidungen.
gegeben, so besteht die
Einzelworterkennungsaufgabe darin, die Identität
des mutmaßlich gesprochenen Wortes zu ermitteln. Dabei stehen nur
Elemente des Erkennungswortschatzes W zur Debatte. Das Ziel der
Auslegung eines Worterkenners ist die Minimierung der
Wortfehlerrate,
also der zu erwartenden Häufigkeit falscher Wortentscheidungen.
Mustervergleich. Die frühesten Worterkennungssysteme folgten
der Architektur des Abstandsklassifikators (siehe Kapitel 1). Jeder Wortschatzeintrag
wurde durch ein ReferenzmusterYl
(genannt Prototyp oder Schablone) repräsentiert. Jedes
ist die Merkmalvektorfolge einer ausgewählten Realisierung des Wortes,
die während der Systemdimensionierungsphase erworben wurde. Um die
potentiellen Aussprachevariationen angemessener zu erfassen, kann jedes
Wort auch durch mehrere Prototypen ![]() vertreten werden. Die Wortentscheidung erfolgt dann auf der Grundlage der
Abstandberechnung, bzw. dem Minimum zugunsten des Wortes
mit dem bestpassenden Referenzmuster.
vertreten werden. Die Wortentscheidung erfolgt dann auf der Grundlage der
Abstandberechnung, bzw. dem Minimum zugunsten des Wortes
mit dem bestpassenden Referenzmuster.
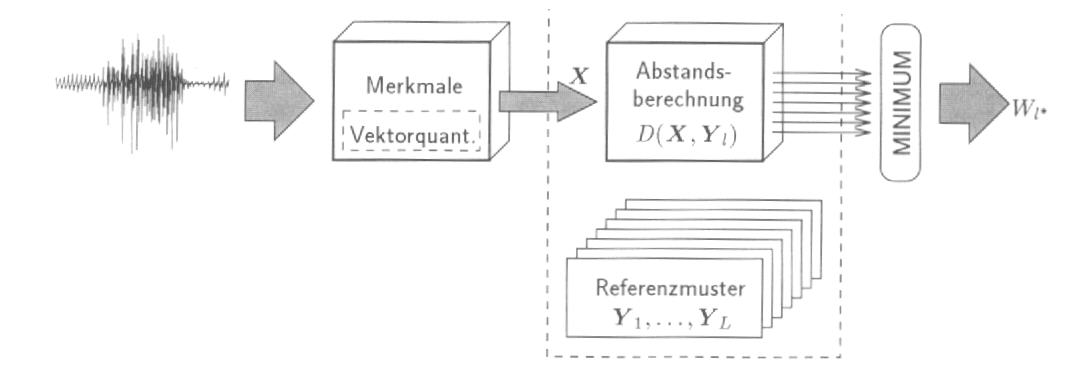
Abb.3: Einzelworterkennung durch Mustervergleich
Den Abstand D(X,Y) zwischen der Eingabesequenz und einer
Referenzfolge Y =
unterschiedlicher Dauer bestimmen
wir als Summe lokaler Distanzen
= entlang
eines geeigneten Zeitverzerrungspfades zwischen den Vektorfolgen; die lokale
Abstandsfunktion d(*,*) wird meistens durch die euklidische Metrik realisiert.
Die geeignete Verzerrungsfunktion für diesen Zweck sollte
X
in seiner ganzen Länge auf Y abbilden, gewisse Monotonie-
und Stetigkeitseigenschaften in der
t-Skala und der s-Skala
gehorchen und natürlich den geringsten Gesamtabstand verursachen.
Diese an und für sich hochkomplexe diskrete Optimierungsaufgabe -
auch unter den genannten Einschränkungen wächst die Zahl der
kombinatorisch möglichen Pfade exponentiell mit der Prototyplänge
- gehorcht dem uns schon bekannten Optimalitätsprinzip und läßt
sich also durch die
Dynamische Programmierung lösen. Für
die kumulativen Distanzen
= D()
zwischen Anfangsstücken der Vektorfolge X,Y gilt die
Rekursionsformel
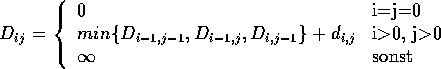
und die Gesamtdistanz ist daher mit einem Aufwand von nur O(T*S) Rechenoperation zu bestimmen.
Im vorigen Beispiel waren nur drei Punkte als Vorgänger möglich,
aber theoretisch betrachtet gibt es mehrere mögliche Suchschemata.
Rabiner führt 7+1 Typen auf (siehe Abbildung 4), wobei in der Praxis
der einfache Typ I die meiste Verwendung erfährt.
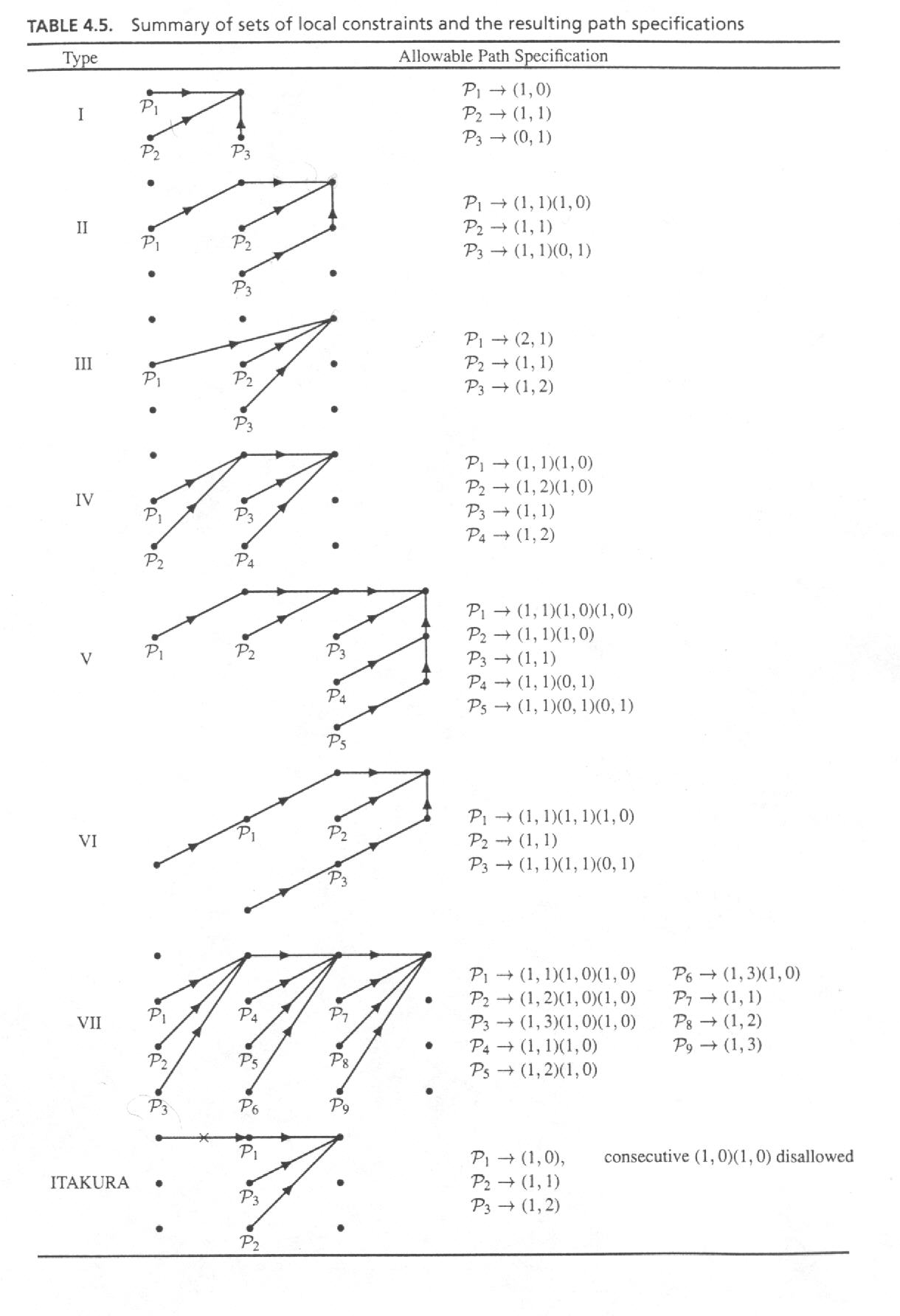
Abb.4: Verschiedene Arten der Suchschemata
Pfadbeschneidung. Obwohl die DP-Algorithmen im Vergleich zur vollständigen Berechnung aller möglichen Pfade eine drastische Reduktion an Rechenaufwand erzielen, kann die zu erbringende Rechenleistung besonders beim Vergleich eines unbekannten Wortes mit einer großen Zahl möglicher Kandidaten beträchtlich sein. Jede mögliche Rechenersparnis, die nicht die Genauigkeit des Erkennungsergebnisses beeinträchtigt, ist deshalb wünschenswert. Eine mögliche Rechenersparnis resultiert aus folgender Tatsache: bei den Spaltenberechnung in der folgenden Abbildung ist es sehr unwahrscheinlich, daß der beste Pfad eines richtig zugeordneten Wortes durch einen Punkt verlaufen wird, dessen Gesamtabstand den niedrigsten Spaltenwert bedeutend übersteigt. Die Rechenersparnis wird dadurch erreicht, daß Punkte mit hohen Abstandswerten nicht weiter verfolgt werden. Dieses Verfahren wird auch Pfadbeschneidung genannt (eng. ,,pruning``). Als Folge wird nur noch ein schmaler Streifen möglicher Pfade beiderseits des optimalen Pfades berücksichtigt.