|
|
|
Database Connectivity in WebLogicTMThis paper reviews DBMS client-server architecture, introduces the multitier concept, and explains how WebLogic's JDBC is ideally suited for creating data-oriented or multitier applications for both intranet and Internet applications, particularly on the World Wide Web.
Relational database management systems (RDBMS or DBMS) represent all data in a uniform way as rows or records of data in tables. All operations on the data are done using commands in SQL (Structured Query Language). (For more detailed information about the client-server model, see Lloyd Taylor's Client/Server FAQ.) The first DBMSes, developed in the early 1980s, had a simple but inefficient scheme: each application program that wanted to access a relational database called its own data management libraries, or started its own invocation of the DBMS program. There were several disadvantages to this approach; it was very wasteful of computer resources, it was not suitable for local area networks (LANs), and could provide only limited support for transactions across multiple programs and users. In the mid 1980s the database industry began a shift to a client-server architecture. In the client-server model, a single multithreaded DBMS server starts up before any client program. Client requests, in the form of SQL queries or updates, are received over the LAN by the DBMS server, which sends back SQL rows or status information in response to each request. The client-server model proved to be far more efficient and successful in coordinating and managing computer and network resources. For the past decade, client-server architecture has enjoyed great success. But as computing has evolved in the 1990s, a number of problems with traditional two-tier architecture have become apparent:
To address these problems, a new multitier architecture has evolved for the 90s. Multitier architecture (sometimes called three-tier) extends the standard client-server architecture (also known as two-tier) by placing a multithreaded application server between the client and the DBMS. Clients communicate with the DBMS through the application server, using high-level, vendor-independent requests and replies. The application server is responsible for executing those requests, and makes calls as needed into each DBMS vendor's client library to communicate with DBMSes. Properly applied, multitier architecture can solve each of the problems of the traditional two-tier client-server.
WebLogic brings the full power of multitier architecture to the Java
development environment with WebLogic, its flagship Java
application server. In addition to its many other server services,
including event handling and remote-server-side class invocation for
distributed processing, WebLogic's multitier framework also supports
database connectivity. All WebLogic applications may share cooperative
access to many services inside the WebLogic framework: event handling
transaction control, remote method invocation, name and directory
services, security, global logging, instrumentation, and
resource management.
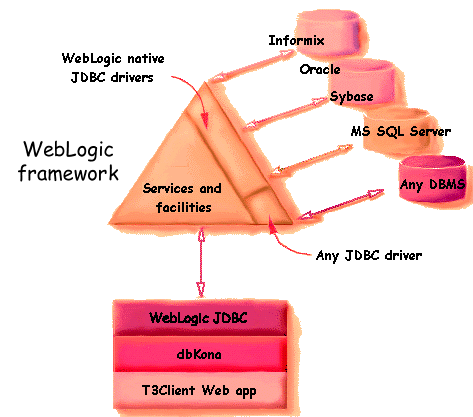
For database connectivity, WebLogic licenses a subset of WebLogic's
features called WebLogic
ExpressTM. WebLogic Express
includes WebLogic JDBC, WebLogic's pure-Java, multitier implementation
of the JavaSoft JDBC API, also offers security, built-in HTTP servlet support, and client access via multiple
protocols, including HTTP tunneling and IIOP. With the multitier WebLogic JDBC driver to
provide connectivity between the client and the WebLogic Server, the
developer also uses one or more JDBC drivers to connect the WebLogic
Server to remote DBMSes, to which clients of the WebLogic Server have
access to database data, as well as other sources of data that are
being handled within WebLogic.
WebLogic JDBC handles multiple requests to heterogeneous databases for
multiple clients via any JDBC-compliant database driver, (including
the
WebLogic jDriver for OracleTM native JDBC driver).
In addition, WebLogic's dbKonaTM offers a higher level of abstraction
for database access than JDBC. All of these products work together to
provide database access services in WebLogic.
WebLogic solves several problems in integrating database data in a
distributed, networked, Web-based intranet or internet environment:
One of the most important tasks of a database system is to perform
transactions. A transaction is a set of operations, all of
which must be completed in order (known as a commit), or not
completed at all (a rollback). The classic example is a
money transfer from one bank account to another, where the same amount
must be debited from the first account as credited to the second
account. In the DBMS client-server environment, a client application
must perform the following steps to do a transaction.
A transaction can be optionally tagged with an ID. Ending a session
while a transaction is pending causes an automatic ROLLBACK.
As described in the steps above, a client-server transaction is
inherently a session in which each step requires the context
information (or state) that was created by previous steps. The
necessity to maintain a session makes DBMS computing on the Web
difficult, as the next few paragraphs explain.
All Web browsers and servers use a protocol called HTTP to
communicate. HTTP is stateless; that is, an HTTP server has no
memory of previous requests. For example, if you are viewing a Web
page in your browser, and you click on a link that requests
http://bigserver.com/this, and then 5 minutes later click on a
link that requests http://bigserver.com/that, the server at
bigserver.com has no way of knowing that the two requests
this and that came from the same person browsing the
same page.
For most applications, this stateless property of HTTP is a
benefit that permits clients and servers to be written with simple
logic and run lean with no extra memory or disk space taken up with
information from old requests. Unfortunately, however, the stateless
property of HTTP makes it difficult to support the concept of a
session that is essential to basic DBMS transactions.
Developers have come up with various schemes to compensate for the
stateless nature of HTTP, such as returning Web pages with hidden
fields containing transaction IDs, and using Web page forms where all
the information is entered locally and then submitted it as a single
transaction. All of these schemes are limited in the kinds of
applications they support and require special extensions to the HTTP
servers. WebLogic provides a set of
elegant and simple solutions for transaction processing on the Web.
WebLogic Express fully supports DBMS transactions in two ways.
After release 2.4, WebLogic supports secure sessions between a WebLogic
Server and its clients via Secure Socket Layer (SSL), which offers
both encryption and authentication services. In addition, WebLogic also
offers tunneling of Java-to-Java WebLogic Connections over HTTP for
transfirewall and transproxy access.
This paper has shown how WebLogic products within WebLogic's multitier
framework are ideally suited for Java database connectivity in the
multitier client-network, for both intranet and internet business
applications.
|
|
|
|
Copyright © 2000 BEA Systems, Inc. All rights reserved.
|