|
|
|
Using XML With WebLogic Server
Like HTML, XML uses tags to describe content. However, rather than focusing on the presentation of content, the tags in XML describe the meaning and hierarchical structure of the data. This allows for sophisticated data types, as required for efficient data interchange between different programs and systems. By providing a facility to define new tags, XML is also extensible. The XML syntax uses matching start and end tags to mark up information. Information delimited by tags is called an element. Elements may have attributes in the form of name-value pairs. The syntactic meaning associated with the tags of an XML document can be defined in a Document Type Definition (DTD). A DTD describes what elements and attributes are valid in an XML document, and in what context they are valid. In other words, a DTD specifies which tags are allowed within certain other tags, and which tags and attributes are optional.
Because of XML's extensibility, it is a very effective tool for normalizing the format of data interchange between vertical industries. A typical scenario involves message brokers and workflow engines responsible for coordinating transactions that involve multiple industries or departments within an enterprise. XML can be used to combine data from disparate sources into format that is understandable by all parties.
When an application invokes a DOM parser, the parser processes the entire document, creating an in-memory object model which the application can process in any fashion it chooses. The DOM approach is most useful for more complex documents since it does not require the developer to interpret every element. We will discuss the DOM API in more detail in Generating XML documents and Parsing XML documents. For the Javadocs of the DOM API, please refer to Additional resources.
Generating XML documentsIn this section, we will briefly discuss methods for programmatically generating XML documents. This discussion does not include the delivery of static XML documents or what makes an XML document well-formed or valid. For information on these topics, please see the Additional resources section.
// send xml to servlet
pw.println("<?xml version='1.0'?>");
// set document type declaration
pw.println("<!DOCTYPE stocktrade SYSTEM '"+serverURL
+"stocktrade.dtd'>");
// set stock trade instructions
pw.print("<stocktrade ");
pw.print("action = "+ (buy ? "'buy' " : "'sell' "));
pw.print("symbol = "+ (webl ? "'WEBL' " : "'INTL' "));
pw.print("numShares = '"+ line +"'");
pw.println(" />");
Using DOM APIThe DOM API provides methods for building and modifying entire XML documents in memory. Once a document has been generated, you simply write the document to the appropriate output stream. This will be discussed further in Passing XML documents between applications.In the XML via JMS example, Client creates an XML document using the DOM API as shown below. // create a new XML document
XmlDocument xmlDoc = new XmlDocument();
// set the document type declaration
xmlDoc.setDoctype(
"weblogic-examples-xml-jms-dtd",
"http://www.weblogic.com/docs51/examples/xml/jms/workflow.dtd",
"");
// assign elements and attributes
Element root = xmlDoc.createElement("workflow");
root.setAttribute("message", message);
root.setAttribute("sender", username);
root.setAttribute("status", status);
xmlDoc.appendChild(root);
Since the DOM API allows you to work with an entire XML document in memory,
it is easy to modify and re-use the document. In the
XML via JMS example,
AdminClient receives the document
sent from Client, modifies a couple of
the element atttributes, then re-sends the document back to
Client.
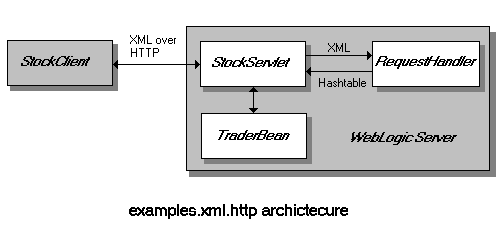
StockClient connects to the StockServlet and sends an XML document via the POST method. The following code segment from StockClient obtains the URL to the servlet from the argument list, opens a URL connection, obtains the output stream from the connection, and prints the first couple of lines of the XML document to the output stream. URL url = new URL(args[0]);
.
.
.
URLConnection urlc = url.openConnection();
urlc.setDoOutput(true);
urlc.setDoInput(true);
PrintWriter pw = new PrintWriter(new
OutputStreamWriter(urlc.getOutputStream()), true);
// send xml to servlet
pw.println("<?xml version='1.0'?>");
// set document type declaration
pw.println("<!DOCTYPE stocktrade SYSTEM '"+serverURL
+"stocktrade.dtd'>");
StockServlet processes the
XML sent from StockClient and returns the results
in another XML document. The following code from StockClient
reads the resulting XML document from the URL connection's input stream and parses it.
For more information on parsing an XML document see Parsing XML documents.
parser.parse(new InputSource(new BufferedReader(
new InputStreamReader(urlc.getInputStream()))));
Now lets look at how StockServlet reads in the
XML document sent from StockClient.
As mentioned above, StockClient sends an XML
document within the HTTP request header (the POST method).
Within StockServlet's
doPost method, the following code obtains
a BufferedReader from the
request and
passes to a RequestHandler object to be parsed.
For more information on parsing an XML document see
Parsing XML documents.
RequestHandler rh = new RequestHandler();
try {
rh.parseXML(request.getReader(), parserClass);
}
After processing the request, StockServlet
returns an XML document to StockClient by using
a PrintWriter obtained from the HTTP response
as shown below.
PrintWriter responseWriter = response.getWriter();
responseWriter.println("<?xml version='1.0'?>");
responseWriter.println("<!DOCTYPE traderesult SYSTEM '"
+serverURL+"traderesult.dtd'>");
.
.
.
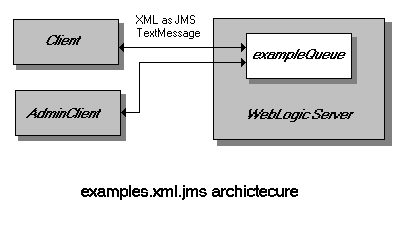
Using JMSIn the XML via JMS example, the Client and AdminClient applications send XML documents to each other as JMS TextMessages as shown in the diagram below.
In Using DOM API, we discussed how an entire XML can be created in memory. Once Client has generated the document, it writes the document to a String which is used to set the message text prior to sending the message to the JMS queue as shown below. // write document to a String and send as a JMS text message
StringWriter sw = new StringWriter();
try {
xmlDoc.write(sw);
msg.setText(sw.toString());
msg.setStringProperty("messageTo", sendTo);
qsender.send(msg);
} catch (Exception e) {
e.printStackTrace();
}
When a message is received, the text is extracted from the message then parsed as shown below. For more information on parsing an XML document see Parsing XML documents. // get the message and parse String msgText = ((TextMessage) message).getText(); parser.parse(new InputSource(new StringReader(msgText)));
SAX parsers must have an associated handler class to handle parsing events. The org.xml.sax.HandlerBase class is the default base class for handlers. This class contains methods that are called by the parser as a document is parsed. By default, these methods do nothing. In the XML over HTTP example, StockServlet receives XML documents via the POST method. The helper class RequestHandler extends HandlerBase and is used to handle all parsing events. After a document has been parsed, RequestHandler returns an object that is used by StockServlet to access the document data and finish processing the request. As an XML document is parsed, the event handling methods of RequestHandler are used to build a Hashtable named trade that contains all of the document data in name-value pairs. The following method from RequestHandler is called whenever a new element is encountered by the parser. public void startElement(String name, AttributeList attrs)
throws SAXException {
if (attrs != null) {
int len = attrs.getLength();
for (int i = 0; i < len; i++) {
trade.put(attrs.getName(i), attrs.getValue(i));
}
}
}
After the document is parsed, the getData
method is called on RequestHandler
to obtain the Hashtable
as can be seen in this code segment from
StockServlet.
RequestHandler rh = new RequestHandler();
try {
rh.parseXML(request.getReader(), parserClass);
}
.
.
.
java.util.Hashtable trade = rh.getData();
After obtaining the Hashtable,
StockServlet uses the data to
operate on TraderBean and
fulfill the stock trade request.
Using DOM APIParsing an XML document with a DOM parser results in a org.w3c.dom.Document object. This is a hierarchical object model of the document that can be traversed, read, and modified using the DOM API.The XML over HTTP example uses the Project X parser from Sun. This DOM implementation uses a SAX parser with a special document handler, XMLDocumentBuilder that builds the Document object when the document is parsed. The following code from Client creates a parser, sets an EntityResolver (this will be discussed in Implementing EntityResolver), sets the document handler, and obtains and parses the document. // obtain a DOM parser and associate the
// resolver and document builder
Parser parser = new com.sun.xml.parser.Parser();
// use custom entity resolver to locate the DTD when parsing
ResourceEntityResolver rer = new ResourceEntityResolver();
rer.addEntityResource(
"weblogic-examples-xml-jms-dtd",
"workflow.dtd",
getClass());
parser.setEntityResolver(rer);
XmlDocumentBuilder builder = new XmlDocumentBuilder();
builder.setDisableNamespaces(true);
builder.setParser(parser);
// get the message and parse
String msgText = ((TextMessage) message).getText();
parser.parse(new InputSource(new StringReader(msgText)));
// get document data and display results to console
Document doc = builder.getDocument();
Validation is a powerful tool for ensuring that an XML document contains all of the necessary information required by your application. XML parsers will automatically check a document to ensure that it is well-formed, however to validate a document, you must include a DTD within your document. This is handled within the document type declaration which was introduced in Generating XML documents. Document type declarations take the general form: <!DOCTYPE NAME SYSTEM "file"[]>The use of the document type declaration varies depending on the subsets used to house the DTD. For external subsets, the SYSTEM term is used to indicate that the following system identifier URI, "file", must be read and resolved. For internal subsets, the DTD must be contained explicitly within the [ and ]. NAME defines the name of the document type. When using an external subset to house a DTD, you must consider how the parser will resolve the external entity. This is discussed in Resolving external entities
In the example, both the client and servlet programatically determine the URL of the server as shown in the following code segment from StockClient. String serverURL = args[0];
// Remove the servlet name from this String
// This will be used to locate the dtd
serverURL = serverURL.substring(0, serverURL.indexOf("StockServlet"));
After StockClient connects to the servlet, the name
of the servlet is stripped
off of the URL resulting in the URL to the server. The server URL is then used to
locate the stocktrade.dtd in the
following line that generates the document type declaration.
pw.println("<!DOCTYPE stocktrade SYSTEM '"
+serverURL+"stocktrade.dtd'>");
As a result of including the DTD within the document type declaration, the parser
validates the XML document and notifies
the document handler if any problems are encountered.
Implementing EntityResolverSome applications will require customized handling for external entities. By implementing EntityResolver, your application will have the ability to locate and/or modify the external entity before it is included within the document by the parser.In the XML via JMS example, the DTDs are housed in external subsets. ResourceEntityResolver implements EntityResolver and uses the classloader to locate the DTDs. This is done by first establishing a unique public identifier for the DTD. This identifier is included in the document type declaration and is used by ResourceEntityResolver to determine which resource is being requested. ResourceEntityResolver also associates the DTDs with the client class that uses them (see the code segment presented in Using DOM API). Prior to running the example, the DTDs are copied to the directory containing the client class. When the parser reads the document type declaration, it passes the public identifier to ResourceEntityResolver through the resolveEntity method as shown below. public InputSource resolveEntity(String publicId, String systemId)
throws SAXException, IOException
{
InputSource ins = null;
EntityResource resource =
(EntityResource) entityCatalog.get(publicId);
InputStream resin = resource.getResourceAsStream();
if (resin == null) {
// we didn't find the local resource, so we return null to
// signal the parser that it must resolve the entity itself.
return null;
}
ins = new InputSource(resin);
ins.setPublicId(publicId);
return ins;
}
The getResourceAsStream method
utilizes the classloader to locate the associated
class (and therefore the DTD). It then converts the DTD to an
InputStream to be handed off to the parser.
If the entity is not resolved, ResourceEntityResolver
returns a null indicating to the
parser that it must use the system identifier to resolve the entity.
In the BizTalk server example, DOMIncomingMessage is a wrapper class for BizTalk documents and provides efficient access to data stored in incoming documents. DOMOutgoingMessage provides an easy way to generate BizTalk documents.
Within this architecture, the servlet acts as a mediator between the client and the EJBean, and XML is the serialization format for communication between the client and servlet. This promotes loose coupling of the client and EJBean by keeping the objects from referring to each other explicitly, and it allows you to vary their interaction independently. The client does not need to know anything about the EJBean interfaces. In fact, the only requirements for the client application are a knowledge of the DTD governing the XML structure, and the ability to read and write to an HTTP connection. Since these requirements are platform- and language-neutral, this greatly reduces client dependency and increases inter-operability of the system. In the XML over HTTP example, StockServlet acts as the mediator between StockClient and TraderBean. StockClient has no knowledge of the TraderBean interfaces. However, by connecting to StockServlet and passing XML documents that are valid with respect to the stocktrade.dtd, the trade is executed on behalf of StockClient.
XSL is an XML-based language that is understood by an XSL processor. It provides elements that define rules for how one XML document is transformed into another XML document. An XSL processor accepts as input an XML document and an XSL document. The template rules contained in an XSL document have patterns specifying the XML tree to which the rule applies. The XSL processor scans the XML document for patterns that match the rule, then applies the template to the appropriate section of the original XML document. Some XSL processors also support output as HTML and/or raw text, though the standard does not required them to do so. A common use of XSL transformation is in applications that support multiple client types. For example, suppose you have an web-based application that supports both browser-based clients and Wireless Application Protocol (WAP) clients. Since these clients understand different markup languages (HTML and WML respectively), your application must be able to deliver content that is appropriate for the given user. The most efficient way to handle this is to have your application produce an XML document when responding to a client. Prior to sending the response back to the client, the XML document can then be transformed into HTML or WML depending on the client's browser type. The browser type can be determined by examining the User-Agent request header of an HTTP request. See the SnoopServlet example included in the examples/servlets subdirectory of your WebLogic distribution for an example of accessing this type of header information. This architecture helps to concentrate the effort required to support multiple client types into the development of the appropriate XSL stylesheets. Additionally, it allows your application to easily adapt to other clients types if required. For additional information on XSL, see Additional resources.
|
|
|
|
Copyright © 2000 BEA Systems, Inc. All rights reserved.
|