




Es gibt auch eine Reihe von Möglichkeiten, Ergebniswerte des Datentyps CHAR zu bearbeiten.
Für verschiedene Anwendungsfälle kann es nötig sein, Werte umzucodieren, weil es verschiedene Operatoren verlangen.
CHR - NUM Konversion von Zeichenwerten in Zahlen und umgekehrt.
Beispiel: Suchen nach Mustern in Ziffernfolgen
SELECT * FROM hotel
WHERE CHR(hnr) LIKE '1??'
UPPER - LOWER Übersetzung von Kleinbuchstaben in Großbuchstaben (und dadurch eine Vereinheitlichung der Buchstabenart) und umgekehrt.
Beispiel: Suchen nach Werten unabhängig von der Groß-/Kleinschreibung
SELECT * FROM hotel
WHERE UPPER (name) = 'FLORA'
ASCII - EBCDIC Umcodierung eines Zeichens, das in ASCII verschlüsselt ist, in die entsprechende EBCDIC-Darstellung und umgekehrt.
Beispiel: Ausgabe einer sortierten Ergebnistabelle in EBCDIC-Reihenfolge
SELECT EBCDIC (name) FROM
WHERE ...
ORDER BY 1
S. a. Kapitel 'Anordnung der Zeilen' (2.5).
MAPCHAR Umcodierung von länderspezifischen Buchstaben in eine andere Repräsentation. Dies wird verwendet, um eine sinnvolle alphabetische Einsortierung zu ermöglichen.
ALPHA Umcodierung eines Zeichens, das in ASCII oder EBCDIC verschlüsselt ist, in eine andere in der DEFAULTMAP festgelegte Ein- oder Zwei-Zeichen-Darstellung. Die Funktion greift intern auf MAPCHAR zurück und nimmt zusätzlich eine Umwandlung in Großbuchstaben vor. ALPHA dient ebenfalls zur Beeinflussung der Sortierfolge.
HEX Umcodierung in die hexadezimale Darstellung.
CHAR Umcodierung eines Datums- oder Zeitwerts in eine Zeichenkette.
SOUNDEX Umcodierung einer Zeichenkette in eine Repräsentation, die der sogenannte SOUNDEX-Algorithmus erzeugt. Diese Darstellung kann verwendet werden, wenn der Anwender die Schreibweise eines Suchbegriffs nicht genau kennt ("klingt wie").
VALUE Umsetzung von NULL-Werten in einen anderen Wert. Im folgenden Beispiel taucht die Anrede nicht in der Ausgabeliste auf, und es soll bei Firmen anstelle des NULL-Werts als "Vorname" die Bezeichnung 'Firma' ausgegeben werden.
SELECT VALUE (vorname, 'Firma') vorname,
nachname
FROM kunde
DECODE Umcodierung von Ausdrücken in Abhängigkeit ihrer Werte. Die Bezeichnungen für den Raumtyp sollen in der Ausgabe durch einen in der DECODE-Funktion vereinbarten Code ersetzt werden.
SELECT hnr, preis,
DECODE (raumtyp, 'EINZEL', 1,
'DOPPEL', 2,
'SUITE' , 3)
raum_code
FROM raum
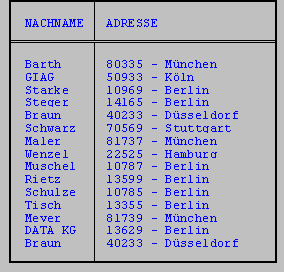
CHAR-Spalten können mit dem Operator '&' verkettet werden.
SELECT nachname, plz & ' - ' & ort adresse
FROM kunde
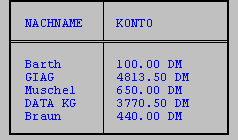
Sollen unterschiedlich lange Werte aus zwei Spalten verkettet, die Leerzeichen zwischen ihnen jedoch reduziert werden, so läßt sich das mit der Funktion TRIM erreichen.
SELECT nachname, TRIM (CHR (konto)) & ' DM' konto
FROM kunde
WHERE konto > 0.00
Mit RTRIM können ein oder mehrere beliebige Zeichen, die als zweites Argument angegeben wurden, von rechts von einem Spaltenwert abgeschnitten werden.
Die Funktion LTRIM bewirkt ein Abtrennen von Zeichen von links ausgehend.
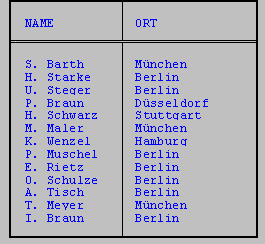
Im folgenden Beispiel wird der Vorname mit Hilfe der SUBSTR-Funktion auf einen Buchstaben verkürzt, mit Abkürzungspunkt und Leerzeichen versehen und mit dem Nachnamen verkettet.
SELECT SUBSTR(vorname,1,1)&'. '&nachname name, ort
FROM kunde
WHERE vorname IS NOT NULL
Mit den Funktionen LFILL bzw. RFILL können Werte vom Typ CHAR auf eine vorgegebene Länge mit einem beliebig wählbaren Zeichen aufgefüllt werden.
SELECT LFILL(vorname,' ',8) vorname, nachname, ort
FROM kunde
WHERE vorname IS NOT NULL AND
ort = 'Berlin'
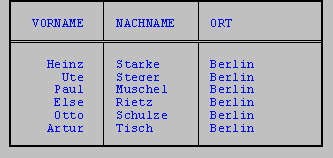
EXPAND erweitert eine Zeichenkette um eine angegebene Zahl von Leerzeichen.
SELECT nachname, konto, LPAD(' ',TRUNC(konto/100),'*',50) graph
FROM kunde
WHERE konto > 0
ORDER BY konto DESC
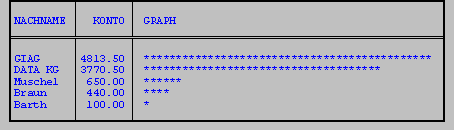
LPAD fügt vor dem ersten Parameter (hier ein Leerzeichen) Sternchen ein. Dies geschieht in der Anzahl des durch 100 dividierten Kontostandes.
Bei RPAD erfolgt das Einfügen der Sternchen an der rechten Seite des Leerzeichens.
Die Kundentabelle wird nach der Länge der Nachnamen sortiert, bei gleicher Namenslänge alphabetisch aufsteigend.
SELECT nachname, LENGTH(nachname) länge
FROM kunde
ORDER BY länge, nachname
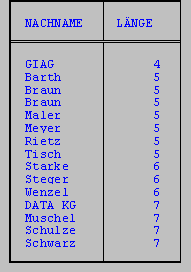
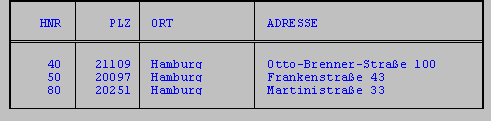
Die Funktion REPLACE ersetzt in der angegebenen Spalte eine Zeichenkette durch eine andere.
Im folgenden Beispiel soll die abgekürzte Schreibweise für Straße durch die vollständige ersetzt werden, um eine einheitliche Darstellung zu erreichen.
SELECT hnr, plz, ort,
REPLACE (adresse, 'tr.', 'traße') adresse
FROM hotel
WHERE ort = 'Hamburg'
TRANSLATE ersetzt in der angegebenen Spalte einzelne Buchstaben durch andere Buchstaben. Dabei wird bei jedem Auftreten der i-te Buchstabe der ersten Zeichenkette durch den i-ten Buchstaben der zweiten Zeichenkette ersetzt. Eine solche - hier zugegebenermaßen nicht sehr sinnvolle - Ersetzung nimmt die folgende Anweisung vor:
SELECT nachname, TRANSLATE (nachname, 'ae', 'oi') name_neu
FROM kunde
WHERE vorname IS NOT NULL AND
ort = 'Berlin'
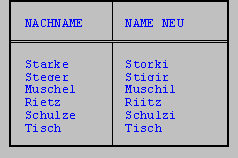
Die Funktion INITCAP liefert, wenn sie auf eine Zeichenkette abgesetzt wird, wiederum eine Zeichenkette zurück, in der jeweils der erste Buchstabe eines Wortes in Groß- und alle weiteren in Kleinbuchstaben erscheinen. Dies kann beispielsweise zur Vereinheitlichung der Schreibweisen von Namen verwendet werden.
SELECT nachname, INITCAP (nachname) name_neu
FROM kunde
WHERE vorname IS NULL

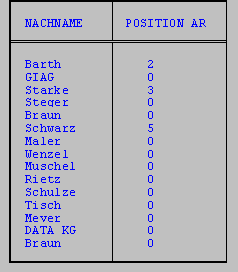
Es soll in einer Zeichenkette nach einem vorgegebenen Substring gesucht werden; die Funktion INDEX liefert die Position dieses Substrings zurück.
Als erster Parameter von INDEX wird die Zeichenkette angegeben, in der die Suche stattfinden soll. Der zweite Parameter spezifiziert den zu suchenden Substring. Optional kann über einen dritten Parameter die Anfangsposition für die Suche und über einen vierten Parameter angegeben werden, nach dem wievielten Auftreten des Substrings gesucht werden soll.
Im folgenden Beispiel soll in allen Nachnamen von Kunden die Position der Zeichenkette 'ar' bestimmt werden.
SELECT nachname, INDEX(nachname, 'ar') position_ar
FROM kunde
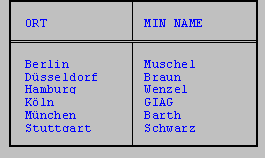
Die bereits für numerische Werte vorgestellten Funktionen MIN und MAX können auch auf Zeichenketten angewandt werden.
So wird in der folgenden Anweisung derjenige Kunde im Ort gesucht, dessen Nachname mit dem, bezogen auf den gewählten Code (ASCII oder EBCDIC), "kleinsten" Buchstaben beginnt. Stimmen die Anfangsbuchstaben überein, wird der Vergleich auf die nachfolgenden Zeichen ausgedehnt. Um eine sinnvolle alphabetische Sortierung insbesondere von Umlauten zu erreichen, sollte jedoch die Funktion MAPCHAR verwendet werden.
SELECT ort, MIN (nachname) min_name
FROM kunde
GROUP BY ort
Die Funktionen GREATEST und LEAST erlauben es, aus einer Liste von angegebenen Werten den größten bzw. kleinsten Wert herauszusuchen. Sie können auf beliebige Datentypen, also auch auf Zeichenketten, angewandt werden. GREATEST ('Max', 'Maler','Mayer') würde beispielsweise 'Mayer' als Ergebnis liefern, da das 'y' als der erste unterscheidbare Buchstabe in der alphabetischen Reihenfolge der "größere" ist.